Redis配置daemonize yes,导致Service反复重启
问题原因:
service 配置项误设为Type=forking(适配守护进程),与daemonize no冲突
问题解析:
在Redis的默认配置文件(redis.conf)中,关于daemonize参数有明确注释,这也是理解问题的重要前提:
# By default Redis does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
# When Redis is supervised by upstart or systemd, this parameter has no impact.
daemonize no # Redis默认值为no,而非yes从默认配置注释可提炼三个关键信息:
1. 默认行为:Redis默认不以守护进程模式运行(daemonize no),需手动设置yes才开启守护进程
2. 守护进程副作用:开启daemonize yes后,Redis会在/var/run/redis.pid写入PID文件,记录后台进程ID
3. 监管机制适配:当Redis被upstart或systemd监管时,daemonize参数本应"无影响"——但实际配置中若忽略此注释,强行设置daemonize yes,反而会触发冲突
核心根源:进程管理权的争夺
这个问题的本质是进程管理权的冲突,是传统守护进程模式与现代系统管理框架systemd之间的理念碰撞,而Redis默认配置的daemonize no,正是为了适配现代监管机制的设计。
传统模式:daemonize yes(与默认配置相反)
在Unix/Linux的传统服务管理中,服务进程通常自己负责"守护进程化"(daemonize):
# Redis传统启动方式
./redis-server /path/to/redis.conf当手动将配置改为daemonize yes时,Redis的行为模式如下:
1. 主进程启动
2. 主进程fork()一个子进程
3. 主进程立即退出(符合守护进程"脱离终端"的设计)
4. 子进程继续在后台运行,成为真正的服务进程,同时在
/var/run/redis.pid写入子进程PID
这种模式在传统的init系统(如SysVinit)下工作正常,因为init只负责启动脚本,不关心进程的生命周期——但与Redis默认配置的"适配现代监管"理念相悖。
现代模式:systemd的管控哲学
systemd的设计理念完全不同,它要求全面接管进程的生命周期管理,这也与Redis默认daemonize no的配置逻辑高度契合:
systemd启动服务后,会紧密监控该服务的主进程(PID 1的直接子进程)
通过监控主进程的状态(是否存活、退出码等)来判断服务运行状态
负责服务的重启、停止、日志收集等全生命周期管理
冲突全过程分解
让我们通过一个时序图,结合Redis的进程行为,清晰展示冲突发生的全过程
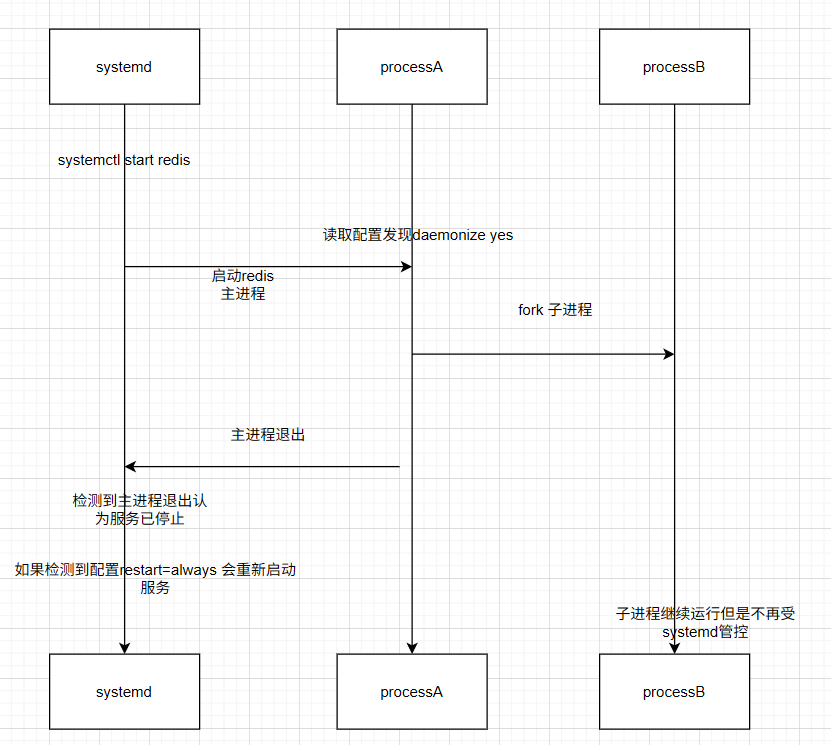
如图所示,冲突的关键在于:systemd监控的"目标进程"(ProcessA)退出了,而真正提供服务的进程(ProcessB)脱离了管控——这正是Redis默认配置不推荐daemonize yes的核心原因:避免与现代监管工具冲突
为什么daemonize no能解决问题?(回归默认配置)
将配置改回Redis默认的daemonize no后,进程行为完全适配systemd的管控逻辑:
systemd启动Redis主进程(ProcessA)
ProcessA读取配置:
daemonize no(遵循默认配置,不触发守护进程逻辑)ProcessA不fork子进程,也不退出(始终在前台运行,不脱离终端关联)
ProcessA自身作为服务主进程,处理所有请求(无需写入PID文件,因无后台子进程)
systemd持续监控ProcessA的状态:
若ProcessA存活:判定服务正常运行
若ProcessA异常退出:按配置触发重启(如Restart=always)
此时,systemd能精准识别Redis的运行状态,实现可靠的监控和生命周期管理——这也印证了Redis默认配置的合理性:daemonize no是为现代系统管理框架量身设计的。
实践与配置建议
在现代Linux发行版中(如CentOS 7+、Ubuntu 16.04+),结合Redis默认配置和systemd特性,推荐以下配置原则:
1. 服务管理方式决定daemonize配置(对照默认值)
2. 完整的systemd服务文件配置(适配daemonize no)
[Unit]
Description=Redis In-Memory Data Store(内存数据库服务)
After=network.target # 网络服务启动后再启动Redis
[Service]
Type=simple # 适配前台运行(daemonize no),systemd直接监控主进程
User=redis # 非root用户运行,降低安全风险(需提前创建redis用户)
Group=redis
# 启动命令:指定Redis可执行文件和配置文件(配置中daemonize=no)
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf
# 停止命令:通过redis-cli发送shutdown指令(优雅停止)
ExecStop=/usr/local/redis/bin/redis-cli -h 127.0.0.1 -p 6379 shutdown
Restart=always # 进程异常退出时自动重启(如OOM、崩溃)
RestartSec=3 # 重启间隔3秒,避免频繁重启
[Install]
WantedBy=multi-user.target # 多用户模式下开机启动3. 关键配置项注意事项(结合Redis特性)
Type=simple:必须与
daemonize no匹配——若误设为Type=forking(适配守护进程),即使daemonize no,systemd仍会等待主进程fork子进程,导致误判服务未启动User/Group:Redis默认配置无用户限制,手动指定低权限用户(如redis)可避免进程被恶意利用
ExecStop:需确保redis-cli能正常连接(如配置密码需补充
-a 密码),否则会导致"停止服务"失败
问题排查步骤(从现象到根源)
当遇到Service反复重启时,可按以下步骤定位问题,验证是否为daemonize配置冲突:
步骤1:查看服务状态与日志(快速判断)
# 1. 查看Redis服务状态(含最近日志)
systemctl status redis -l
# 关键日志识别:若出现"Main process exited, code=exited, status=0/SUCCESS"
# 说明主进程正常退出,大概率是daemonize yes导致
# 2. 查看Redis自身日志(默认路径可在redis.conf中配置,如/var/log/redis/redis-server.log)
tail -f /var/log/redis/redis-server.log
# 关键日志识别:若出现"Background saving started by pid XXXX""Parent exited, bye"
# 说明Redis开启了守护进程模式(daemonize yes)步骤2:验证进程归属(确认脱离管控)
# 1. 查看systemd监控的Redis主进程PID
systemctl show --property MainPID redis
# 输出示例:MainPID=0(说明监控的进程已退出,服务异常)
# 2. 查看实际运行的Redis进程
ps -ef | grep redis
# 输出示例:redis 12345 1 0 10:00 ? 00:00:01 redis-server *:6379
# 关键判断:进程PPID(父进程ID)为1(init进程),而非systemd的子进程ID
# 说明Redis进程脱离systemd管控,是daemonize yes导致的fork子进程步骤3:检查daemonize配置(确认根源)
# 查看redis.conf中daemonize的配置值
grep -n "daemonize" /usr/local/redis/etc/redis.conf
# 若输出"XX:daemonize yes",则确认是配置冲突;改回"daemonize no"后重启服务即可
systemctl restart redis异常场景处理(daemonize no仍重启)
即使配置daemonize no,仍可能出现重启问题,需针对性排查:
场景1:Redis进程因内存不足被Kill
排查:查看系统日志,确认是否因OOM(内存溢出)导致进程被内核杀死:
dmesg | grep -i redis
# 关键日志:"Out of memory: Kill process 12345 (redis-server) score 200 or sacrifice child"解决:
• 优化Redis内存配置:在redis.conf中设置
maxmemory 2GB(根据服务器内存调整),并配置maxmemory-policy allkeys-lru(内存满时淘汰最少使用的键)• 调整系统内存参数:在
/etc/sysctl.conf中添加vm.overcommit_memory = 1(允许内核过度分配内存,避免Redis因内存计算偏差被Kill),执行sysctl -p生效
场景2:systemd服务文件配置错误
排查:检查服务文件中Type参数是否与daemonize no匹配:
grep -n "Type=" /usr/lib/systemd/system/redis.service
# 若输出"Type=forking",则与daemonize no冲突解决:将Type=forking改为Type=simple,重新加载systemd配置并重启服务:
systemctl daemon-reload
systemctl restart redis知识扩展:其他服务的类似配置(避免同类坑)
这种"守护进程与systemd冲突"的问题不仅限于Redis,许多服务都有类似配置,需参考Redis的解决思路:
1. Nginx(类比Redis daemonize)
默认配置:Nginx默认
daemon on;(后台运行,类似Redis daemonize yes)systemd适配:需在nginx.conf中改为
daemon off;(前台运行,类似Redis daemonize no),否则systemd会因监控的主进程退出触发重启服务文件关键配置:
Type=simple(与Redis一致),ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf
2. MySQL(类比Redis默认配置逻辑)
默认配置:MySQL(含MariaDB)默认适配systemd,配置文件中无"daemon化"参数,但部分旧版本存在
skip-systemd参数(类似Redis手动设置daemonize yes)systemd适配:必须注释
skip-systemd(在/etc/my.cnf或/etc/mysql/my.cnf中),否则MySQL会自行daemon化,脱离systemd管控服务文件关键配置:
Type=simple,ExecStart=/usr/sbin/mysqld --defaults-file=/etc/my.cnf
总结
这个看似简单的daemonize配置问题,实际上反映了Linux系统服务管理方式的演进,也印证了Redis默认配置的设计智慧:
默认配置即最佳实践:Redis默认
daemonize no,并非随意设定,而是为了适配现代系统的监管框架(systemd/upstart),避免进程管理权冲突——运维中应优先遵循默认配置,除非有明确的特殊需求理念转变的重要性:从传统"进程自管理"(daemonize yes)到现代"系统统一管控"(systemd),核心是"控制权从进程转移到系统",理解这一转变,才能避免类似"循环重启"的低级错误
日志与进程排查是关键:遇到服务异常时,不要盲目修改配置,应通过
systemctl status、进程PID归属、服务日志等信息定位根源——就像本次问题,从"主进程退出"日志和"脱离管控的子进程"即可快速锁定daemonize配置

